Indexace stránek načítaných přes AJAX
AJAX technologie je dnes na takovém vzestupu, že se z mnoha klasických stránek stávají „portály“, kde se obsah nenačítá klasickým nahráváním celé stránky, ale pouze části stránek pomocí AJAXu. Takové stránky nabízí především rychlejší odezvu pro návštěvníky a také někdy pohodlnější navigaci. Co je ovšem přínosem pro lidi, je noční můrou pro internetové vyhledávače.
Crawler internetových vyhledávačů totiž pochopitelně nedokáže odhadnout, jak je logika stránky vytvořená, jak funguje navigace, kdy se načítá nový obsah a podobně. Jediné, co obvykle dokáže, je následovat odkazy na stránkách (myšleno klasické odkazy v elementech <a>, <link> atd.), které jako odpověď odešlou HTTP response s celou stránkou. Co tedy dělat v případě, že potřebuji AJAXové stránky a zároveň je také zpřístupnit crawlerům?
Sitemap + Hashbang
Jednou z možností, jak takovou situaci vyřešit, je využít XML sitemap a tzv. Hashbang. Sitemap.xml zde zmíním pouze okrajově, jelikož se nyní jedná o naprostý standard a na internetu lze nalézt spoustu lepších článků a informací o jeho struktuře. Jedná se o soubor, který obsahuje seznam URL adres daného webu a tím říká vyhledávačům, na které stránky se mají podívat. Vyhledávač si tedy URL adresy načte a stránky stáhne. Více o sitemap můžete nalézt na oficiálních stránkách www.sitemaps.org/protocol.html.
Nyní k druhé části, která je již zajímavější. Jak přimět webový server a crawler, aby stránky načítané přes AJAX načetly rovnou celé ve finální podobě. K tomuto účelu existuje konvence, která využívá tzv. _escaped_fragment_ parametr, který se přidá k URL. Pokud je tedy aplikace napsaná tak, že dokáže správně na takovýto parametr zareagovat, pošle jako odpověď celou stránku namísto kostry, která se teprve naplní AJAX požadavkem.
Příkladem mohou být nově spuštěné stránky www.sreality.cz. Většina stránek na tomto portálu je načítána právě přes AJAX, ale je zde také ošetřen přístup pro crawlery.
Podíváme-li se na URL adresu detailu jakékoliv nemovitosti, například:
http://www.sreality.cz/detail/prodej/byt/1+1/ostrava-zabreh-krasnoarmejcu/5828700
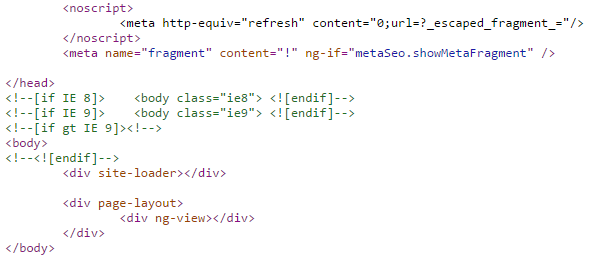
Ukázka kódu stránky připravené pro načtení obrázku pomocí AJAXu.
Zakážeme-li však ve webovém prohlížeči Javascript, dojde k automatickému přesměrování na
http://www.sreality.cz/detail/prodej/byt/1+1/ostrava-zabreh-krasnoarmejcu/5828700?_escaped_fragment_=
Pokud se podíváte na zdrojový kód stránky, ihned uvidíte rozdíl v tom, co se stalo. Zatímco první stránka obsahuje pouze šablonu, do které se data teprve budou vkládat, druhý zdrojový kód již obsahuje kompletní zdrojový kód se všemi informacemi.

Načtený plnohodnotný kód stránky se všemi informacemi.
Meta tag „fragment“
Nyní poslední část, tou je oznámení crawlerovi: „Pozor, stránka je přes AJAX, použij _escaped_fragment_“. Toho lze dosáhnout použitím meta tagu nazvaným „fragment“ <meta name=“fragment“ content=“!“>. Díky tomuto tagu bude crawler posílat všechny odkazy ze stránky s přidaným _escaped_fragment_ na konec URL adresy.
Podpora u vyhledávačů
Teď to nejdůležitější, jak je to s podporou vyhledávačů? Je to dobré. Jak Google, tak i Seznam podporují tento popisovaný postup.
Nyní by vám již nic nemělo bránit ve vytváření AJAXových stránek, které budou přívětivé i pro internetové vyhledávače. Pokud byste se chtěli dozvědět více, níže jsou napsány odkazy na stránky podpory Google a Seznamu.
Google: https://developers.google.com/webmasters/ajax-crawling/